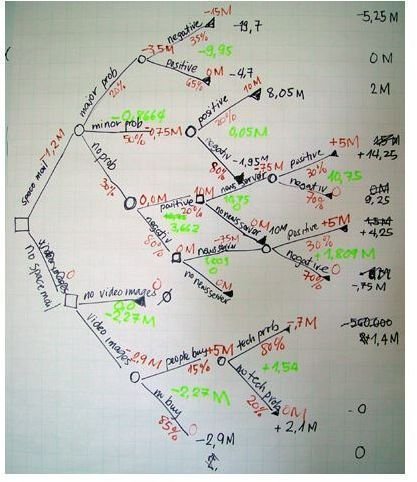
A decision tree is a graphical representation of an algorithm, illustrating all possible decisions, costs, utility, and consequences of an issue, and allows for comparison of such alternatives in one pane. Read on to find out decision tree analysis advantages.
Transparency
One big advantage of the decision tree model is its transparent nature. Unlike other decision-making models, the decision tree makes explicit all possible alternatives and traces each alternative to its conclusion in a single view, allowing for easy comparison among the various alternatives. The use of separate nodes to denote user defined decisions, uncertainties, and end of process lends further clarity and transparency to the decision-making process.
Image Credit: Wikimedia Commons
Specificity
A major decision tree analysis advantages is its ability to assign specific values to problem, decisions, and outcomes of each decision. This reduces ambiguity in decision-making . Every possible scenario from a decision finds representation by a clear fork and node, enabling viewing all possible solutions clearly in a single view.
Incorporation of monetary values to decision trees help make explicit the costs and benefits of different alternative courses of action.
Comprehensive Nature
The decision tree is the best predictive model as it allows for a comprehensive analysis of the consequences of each possible decision, such as what the decision leads to, whether it ends in uncertainty or a definite conclusion, or whether it leads to new issues for which the process needs repetition.
A decision tree also allows for partitioning data in a much deeper level, not as easily achieved with other decision-making classifiers such as logistic regression or support of vector machines.
Ease of Use
Decision trees also score in ease of use. The decision tree provides a graphical illustration of the problem and various alternatives in a simple and easy to understand format that requires no explanation.
Decision trees break down data in an easy to understand illustrations, based on rules easily understood by humans and SQL programs. Decision trees also allow for classification of data without computation, can handle both continuous and categorical variables, and provide a clear indication of the most important fields for prediction or classification, all unmatched features when comparing this model to other compatible models such as support vector or logistic regression.
Simple math can replicate the explanation of the decisions contained in the decision tree easily.
Flexibility
Unlike other decision-making tools that require comprehensive quantitative data, decision trees remain flexible to handle items with a mixture of real-valued and categorical features, and items with some missing features. Once constructed, they classify new items quickly.
Resilience
Another of the decision tree analysis advantages are that it focuses on the relationship among various events and thereby, replicates the natural course of events, and as such, remains robust with little scope for errors, provided the inputted data is correct.
This ability of the decision tree to adopt the natural course of events allows for its incorporation in a variety of application as influence diagrams. Decision trees combine with other decision-making techniques such as PERT charts and linear distributions.
Validation
A decision tree is the best predictive model. It finds use to make quantitative analysis of business problems , and to validate results of statistical tests. It naturally supports classification problems with more than two classes and by modification, handles regression problems.
Sophisticated decision tree models implemented using custom software applications can use historic data to apply a statistical analysis and make predictions regarding the probability of events. For instance, the decision tree analysis helps to improve the decision-making capability of commercial banks by assigning success and failure probability on application data to identify borrowers who do not meet the traditional, minimum-standard criteria set for borrowers, but who are statistically less likely to default than applicants who meet all minimum requirements.
Decision trees provide a framework to quantify the values and probability of each possible outcome of a decision, allowing decision makers to make educated choices among the various alternatives.


